
Frequently Asked Questions
Can't find what you're looking for? Contact help@hirnetwork.org
for assistance.
Help Documents
Guide to Sharing BioSample Resources
Guide to Sharing Dataset & Document Resources
Guide to Sharing Technology Resources
General
Where do resources in the Browser come from?
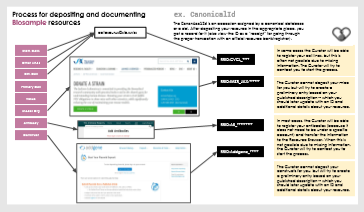
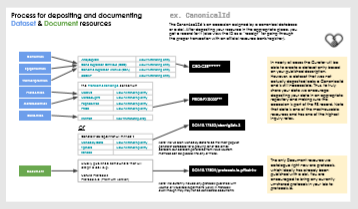
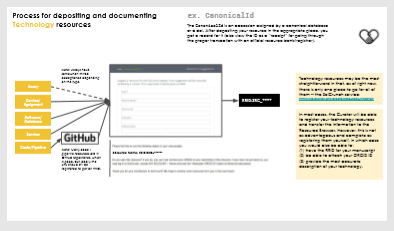
Resources can be submitted by HIRN investigators and the curator in two different processes. Investigators can log in to submit a resource directly through the application form, or they can go through the curator if there is a very large list of resources/need special assistance. The curator also reviews new HIRN publications for resources that are not already in the Browser, which usually appear as part of major releases. Note that creating records in the Browser is a preliminary sharing step to let others know about a resource, but in many cases you should also make sure that a resource is not only known but also available (an important distinction) for true sharing.
So what are the different resource types and their prescribed sharing process?
Please look at slides here (link to slides) for a general overview.
Does the paper have to be published before my resource can appear in the Browser?
No, you are highly encouraged to share resources before publication; you can update the record post-publication to provide additional details such as the PubMed ID.
Do you prioritize certain types of resources?
We don't prioritize between types of resources such as between a Bioreagent or Dataset resource, but we do prioritize novel "produced" resources over "used" resources. We still include "used" resources because the experience/interaction of the scientific community with a resource is still something that needs be tracked in order to provide data about the value and quality of a resource.
How do I learn about the reach or popularity of my resource?
There are currently view counts on each resource page. In the future we might be able to provide other analytical data.
My resource is incorrect?
If you notice an error, you can make corrections by logging in to modify the resource entry directly.
What is an RRID and why are you so concerned with them?
We build upon dkNET’s framework for resource tracking, which makes use of Research Resource Identifiers (RRIDs). From https://dknet.org/about/rrid (where you can also learn more): “RRIDs are persistent and unique identifiers for referencing a research resource and are used for promoting research resource identification and tracking. Catalog numbers change, disappear or can be reused for another resource, but RRIDs always resolve to the same research resource and endure beyond the existence of the research resource itself. It’s an easy and practical method for improving reproducibility, transparency and tracking.”
Can non-HIRN researchers use the Resource Browser?
Absolutely. Although only resources from a HIRN investigator member appear in the Browser (for now), the resources can be viewed by any researcher.
How do I get help with finding a resource if a search doesn't work for me?
If you really need more personal help, email the curator: avu@coh.org.
I want to submit a resource of a different type than currently available?
We adapt the Browser to include new resource types if there is good justification. Use the help email to let us know about your case.
Can you explain how to fill out ratings and usage notes for resource applications?
On our rating scale of 1-5, a rating of 1 generally means the resource did not work at all for a particular application (note that it can work perfectly well for another application, e.g. an antibody may be fine for regular immunohistochemistry but fail for imaging mass cytometry). A rating of 5 indicates that the resource was trustworthy and you can recommend it. Something in between may indicate that the resource technically worked but required a lot of troubleshooting (e.g. a finicky antibody or code/pipeline that was hard to run and didn't have great documentation). You can use Usage Notes to convey information related to the ratings or to convey usage parameters. For antibodies, the most common and suggested minimum usage note is the dilution, in the format "1:xxx".
Technical Corner
What are the differences in the API/Data Access methods?
The REST API is currently most mature and allows data submission while the other two don't. But for most users who are not concerned with posting data, GraphQL could (eventually) be the most convenient way to get data. SPARQL may be the least straightforward, but one advantage of SPARQL will be being able to use the full power of ontology mappings; at the moment, the RDF mappings are still being revised.
.